5 Jaw-Dropping Secrets You’ll Discover in This AWS Lambda Tutorial
AWS Lambda represents a paradigm shift in how developers approach application deployment and scaling. As a cornerstone of serverless computing, Lambda eliminates the need to provision or manage servers, allowing developers to focus purely on writing code that delivers business value. Serverless computing matters because it dramatically reduces operational overhead while providing automatic scaling, high availability, and cost optimization. Instead of paying for idle server time, you only pay for actual compute time used—measured in milliseconds. AWS Lambda is a serverless compute service that runs your code in response to events without requiring you to provision or manage servers. Lambda automatically manages the underlying compute resources, scaling your application by running code in response to each trigger. FaaS represents a cloud computing model where you write stateless functions that execute in response to events. Each function performs a specific task and runs independently, enabling granular scaling and pricing. Lambda functions are event-driven, meaning they execute in response to specific triggers such as HTTP requests, file uploads, database changes, or scheduled events. Understanding event sources is crucial for designing effective serverless architectures. Lambda provides managed runtime environments for multiple programming languages including Python, Node.js, Java, Go, .NET, and Ruby. Each execution environment includes the language runtime, AWS SDK, and basic system libraries. Before creating your first Lambda function, ensure you have: Python Example: Node.js Example: Lambda’s true power emerges when integrated with other AWS services. Here are three essential integration patterns: API Gateway enables you to create RESTful APIs that trigger Lambda functions: S3 event notifications can automatically trigger Lambda functions when files are uploaded: CloudWatch Events can trigger Lambda functions on schedules using cron expressions: For functions with dependencies, create deployment packages: Lambda automatically integrates with CloudWatch for monitoring: Design functions to perform one specific task well. This approach improves maintainability, testability, and debugging while enabling better scaling granularity. Store configuration values, API keys, and database connection strings as environment variables rather than hardcoding them in your function code. When Lambda functions fail, follow these debugging steps: For functions requiring external libraries: Let’s build a practical image resize function triggered by S3 uploads: When users upload images to an S3 bucket, Lambda automatically creates thumbnails and stores them in a separate folder. AWS Lambda transforms how we build and deploy applications by eliminating server management overhead while providing automatic scaling and cost optimization. Key learnings from this tutorial include: Choose Lambda for: Event-driven applications, microservices, periodic tasks, and applications with variable traffic patterns. Consider alternatives for: Long-running processes, applications requiring persistent storage, or workloads needing specific OS configurations. The best way to learn Lambda is through hands-on practice. Start with the AWS Free Tier, which includes 1 million free Lambda requests per month, and begin building your first serverless application today. Transform Your Business With Cloud Excellence ✨ Schedule a session with our experts to discuss your cloud solutions. Additional resources to accelerate your learning:Introduction
What is AWS Lambda?
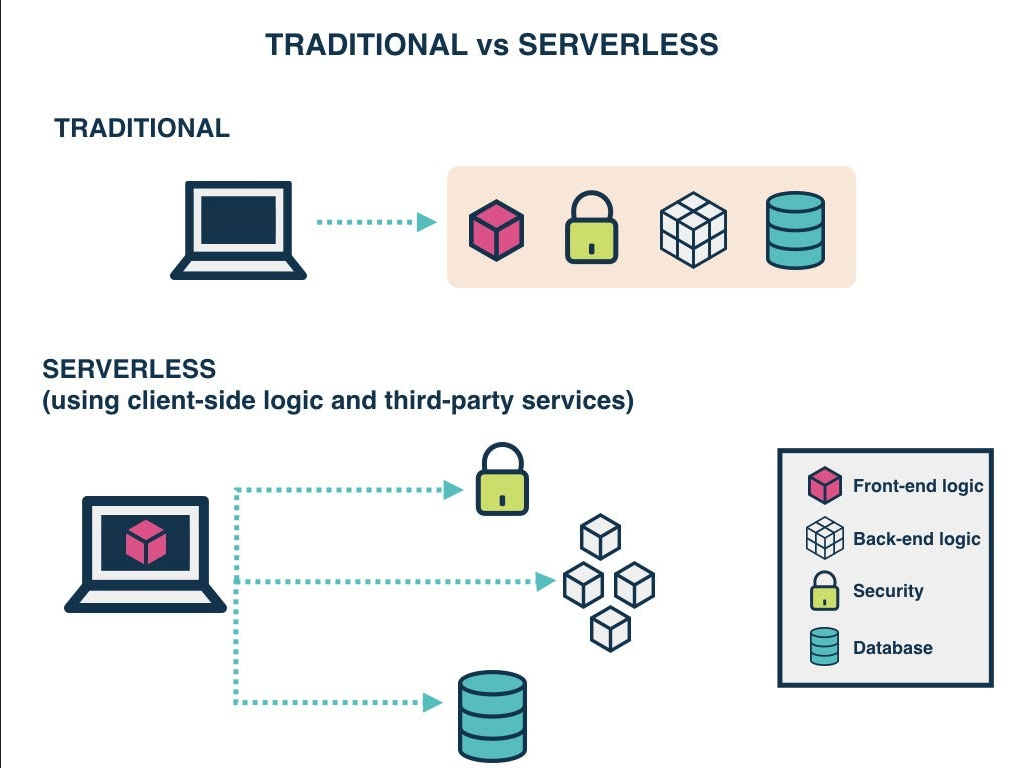
How Lambda Differs from Traditional Server-Based Approaches
Aspect
Traditional Servers
AWS Lambda
Server Management
Manual provisioning, patching, scaling
Fully managed by AWS
Scaling
Manual or auto-scaling groups
Automatic, instant scaling
Pricing
Pay for allocated resources
Pay per execution
Availability
Requires redundancy planning
Built-in high availability
Real-World Use Cases
Key Concepts You Need to Know
Functions-as-a-Service (FaaS)
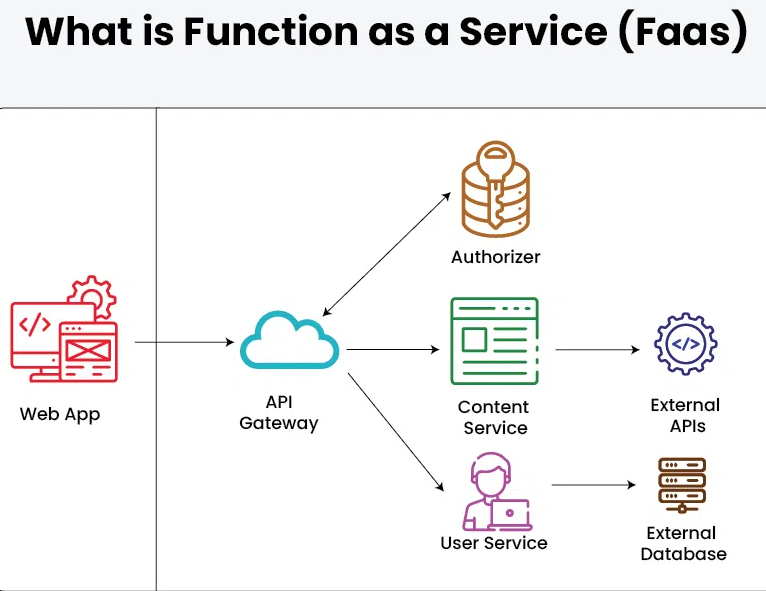
Events and Triggers
Execution Environment
Pricing Model (Pay Per Execution)
Setting Up AWS Lambda
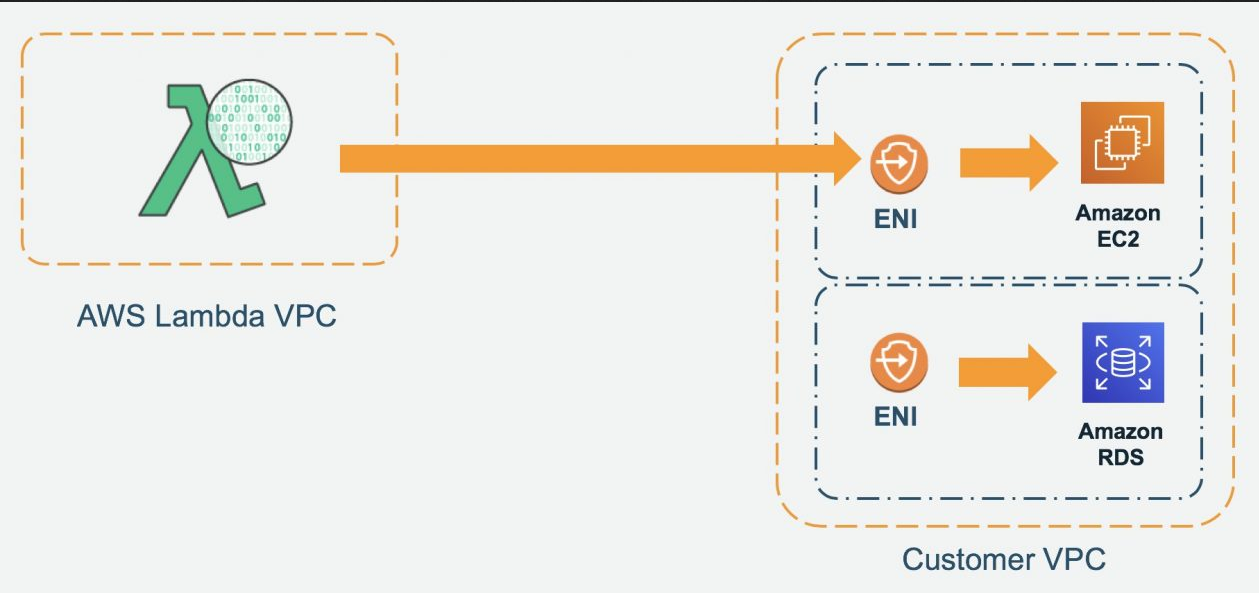 Prerequisites
Prerequisites
Step-by-Step: Creating Your First Lambda Function
Example Code Snippet
import json
import datetime
def lambda_handler(event, context):
# Extract data from event
name = event.get('name', 'World')
# Process the request
message = f"Hello, {name}! Current time: {datetime.datetime.now()}"
# Return response
return {
'statusCode': 200,
'body': json.dumps({
'message': message,
'timestamp': str(datetime.datetime.now())
})
}exports.handler = async (event) => {
const name = event.name || 'World';
const timestamp = new Date().toISOString();
const response = {
statusCode: 200,
body: JSON.stringify({
message: `Hello, ${name}! Current time: ${timestamp}`,
timestamp: timestamp
})
};
return response;
};Connecting Lambda with Other AWS Services
Example: Triggering from API Gateway (Serverless API)
Example: Triggering from S3 Bucket (File Uploads)
def lambda_handler(event, context):
# Process S3 event
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
print(f"File {key} uploaded to bucket {bucket}")
# Process the file (resize, analyze, etc.)
# Your business logic here
return {'statusCode': 200}Example: Triggering from CloudWatch (Scheduled Tasks)
rate(1 hour) or cron(0 12 * * ? *)Deploying & Managing Lambda Functions
Packaging and Deploying Code
# Install dependencies locally
pip install requests -t ./package
# Add your function code
cp lambda_function.py ./package/
# Create deployment zip
cd package && zip -r ../deployment-package.zip .
# Upload via AWS CLI
aws lambda update-function-code \
--function-name my-function \
--zip-file fileb://deployment-package.zipUsing AWS CLI / SAM / Serverless Framework
Monitoring with CloudWatch Logs
Best Practices for AWS Lambda
Keep Functions Small and Single-Purpose
Use Environment Variables
Error Handling and Retries
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
try:
# Your function logic here
result = process_event(event)
logger.info(f"Successfully processed event: {context.aws_request_id}")
return {
'statusCode': 200,
'body': json.dumps(result)
}
except Exception as e:
logger.error(f"Error processing event: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({'error': 'Internal server error'})
}Optimize Performance (Cold Starts, Memory, Timeouts)
Common Pitfalls & Troubleshooting
Debugging Failed Executions
IAM Permission Issues
Managing Dependencies
Real-World Example / Mini Project
Project Overview
Implementation Code
import json
import boto3
from PIL import Image
import io
s3_client = boto3.client('s3')
def lambda_handler(event, context):
for record in event['Records']:
# Extract bucket and object information
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
# Skip if already a thumbnail
if key.startswith('thumbnails/'):
continue
# Download original image
response = s3_client.get_object(Bucket=bucket, Key=key)
image_data = response['Body'].read()
# Resize image
image = Image.open(io.BytesIO(image_data))
image.thumbnail((150, 150), Image.LANCZOS)
# Save thumbnail
buffer = io.BytesIO()
image.save(buffer, format='JPEG')
buffer.seek(0)
# Upload thumbnail to S3
thumbnail_key = f"thumbnails/{key}"
s3_client.put_object(
Bucket=bucket,
Key=thumbnail_key,
Body=buffer.getvalue(),
ContentType='image/jpeg'
)
print(f"Created thumbnail: {thumbnail_key}")
return {'statusCode': 200, 'body': json.dumps('Success')}Workflow Explanation
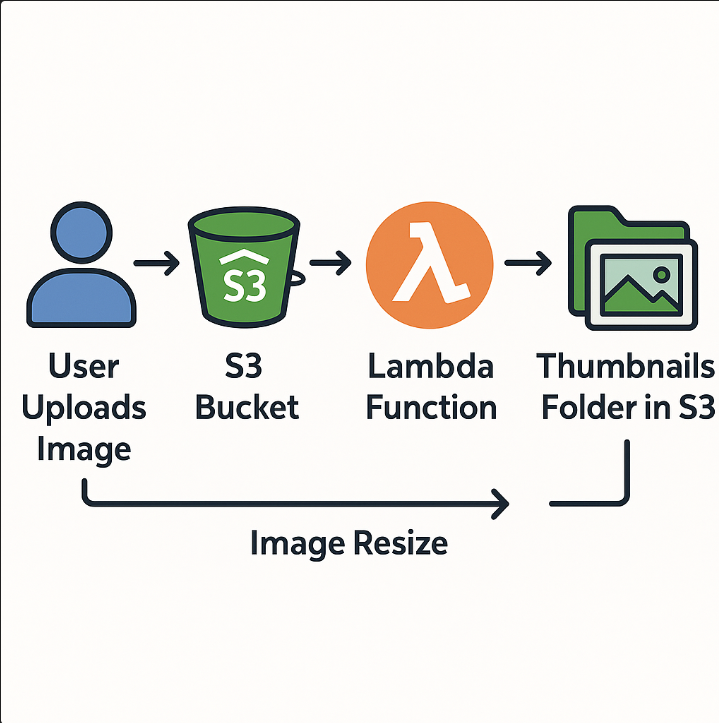
Conclusion
When to Use Lambda vs. Other Compute Services
Ready to Start Your Serverless Journey?